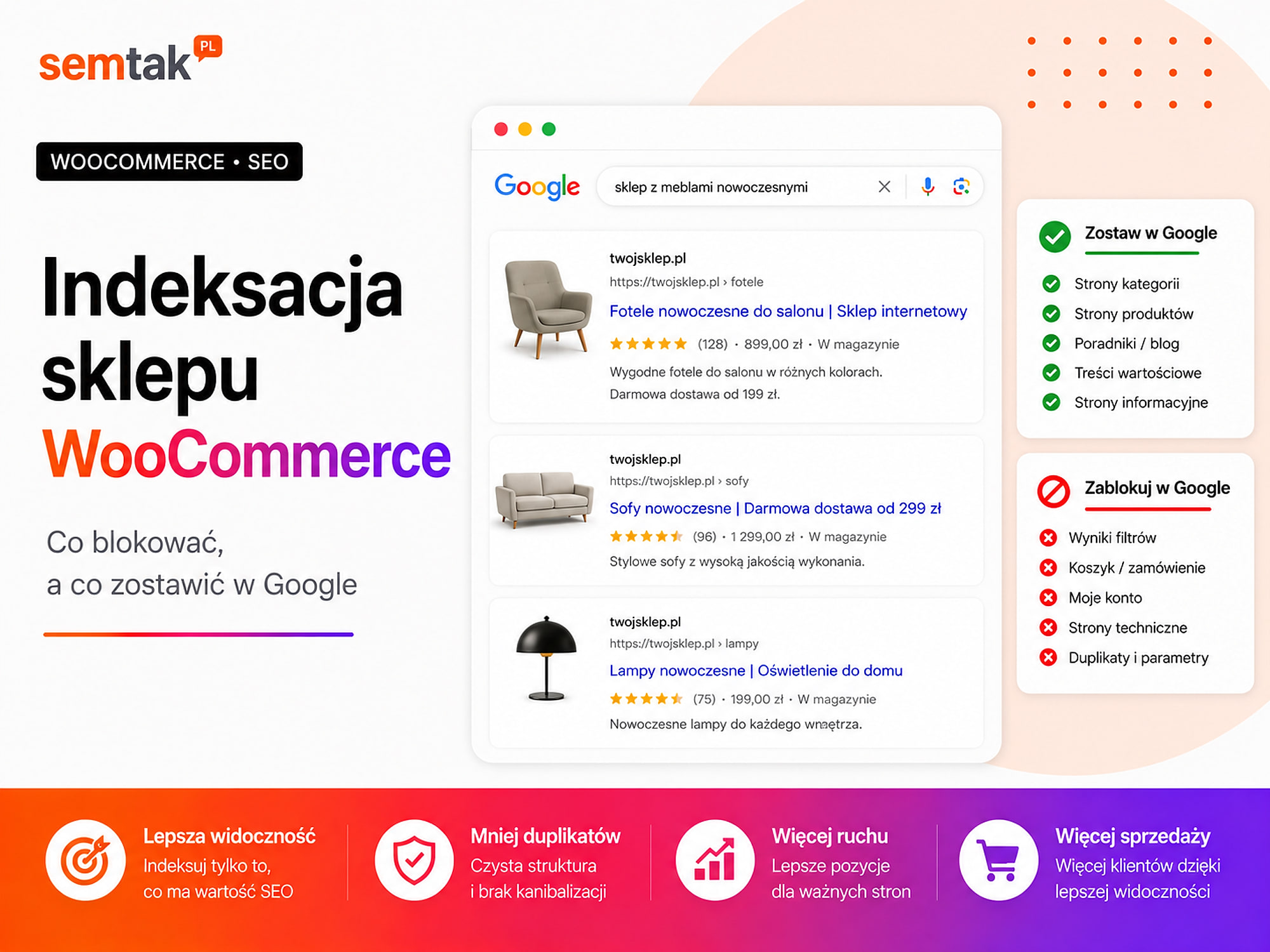
Indeksacja sklepu WooCommerce — co blokować, a co zostawić w Google

Sklep ma 2000 produktów, ale Google Search Console wykrywa 80 000 adresów. W wynikach pojawiają się strony sortowania, puste tagi, koszyk i przypadkowe kombinacje filtrów. Jednocześnie część ważnych kategorii oraz produktów nie trafia do indeksu.
To typowy problem sklepów WooCommerce. Jeden produkt może być dostępny przez kategorię, wyszukiwarkę, filtr, parametr kampanii, wariant i kilka rodzajów sortowania. Dla klienta są to różne sposoby przeglądania tej samej oferty. Dla Google mogą to być osobne adresy URL, które trzeba odwiedzić i ocenić.
Nie chodzi o to, żeby zablokować jak najwięcej stron. Zbyt agresywne ustawienia potrafią usunąć z Google ważne kategorie, odciąć robotowi drogę do produktów albo sprawić, że wyszukiwarka nie zobaczy znacznika noindex.
W tym poradniku pokazujemy, które strony WooCommerce powinny być indeksowane, które zwykle warto wyłączyć z Google oraz kiedy użyć noindex, canonicala, robots.txt, przekierowania 301 albo błędu 404.
Odpowiedź wprost
W indeksie Google powinny pozostawać przede wszystkim: strona główna, ważne kategorie i podkategorie, produkty dostępne albo mogące wrócić do sprzedaży, wybrane strony marek, przygotowane landing page odpowiadające na realne zapytania oraz poradniki i inne wartościowe treści.
Poza indeksem powinny zwykle znajdować się: koszyk, checkout, konto klienta, potwierdzenie zamówienia, wewnętrzne wyniki wyszukiwania, adresy sortowania, większość kombinacji filtrów, cienkie tagi i automatyczne archiwa oraz prywatne i techniczne strony użytkownika.
Nie blokuj wszystkiego w robots.txt. To narzędzie ogranicza odwiedzanie adresów przez roboty, ale nie służy do usuwania stron z wyników. Jeżeli Google ma zobaczyć noindex albo canonical, musi mieć możliwość wejścia na stronę.
W skrócie (TL;DR)
- Indeksacja oznacza, że Google może przechowywać stronę w swojej bazie i wyświetlać ją w wynikach.
- Kategorie, wartościowe produkty, przygotowane strony marek i poradniki powinny być dostępne do indeksowania.
- Koszyk, checkout, konto klienta, wyszukiwarka wewnętrzna oraz przypadkowe filtry zwykle powinny mieć
noindex. robots.txtkontroluje crawlowanie,noindexindeksację, canonical wskazuje preferowaną wersję, a 301 przenosi adres na stałe.- Nie łącz automatycznie kilku mechanizmów naraz. Najpierw określ, czy strona jest duplikatem, została usunięta, czy tylko nie powinna pojawiać się w Google.
- Nie blokuj paginacji bez analizy. Google potrzebuje zwykłych linków do kolejnych stron, aby docierać do głębiej położonych produktów.
- Produkt chwilowo niedostępny zwykle powinien pozostać pod tym samym adresem i zwracać kod 200.
- Sitemap XML powinna zawierać tylko adresy, które mają być indeksowane i zwracają kod 200.
- Komenda
site:daje jedynie szybki podgląd. Dokładniejsze decyzje podejmuj na podstawie Search Console, crawla i logów serwera.
Czym różni się crawlowanie od indeksowania?
Google musi najpierw znaleźć i odwiedzić stronę, zanim będzie mogło zdecydować, czy dodać ją do indeksu. Proces można uprościć do czterech etapów:
- Odkrycie adresu — Google znajduje URL w linku, sitemapie albo na innej stronie.
- Crawl — robot pobiera kod strony.
- Renderowanie i analiza — Google odczytuje treść, linki, canonical, dane strukturalne i ustawienia robots.
- Indeksacja — wyszukiwarka decyduje, czy strona powinna znaleźć się w indeksie i pod jakim adresem.
Strona może więc być znana Google ale jeszcze nieodwiedzona, zostać odwiedzona ale niezaindeksowana, znaleźć się w indeksie, zostać uznana za duplikat innej strony, zostać wykluczona przez noindex albo zniknąć po przekierowaniu lub usunięciu. Samo dodanie adresu do sitemapy nie gwarantuje indeksacji. Z kolei brak strony w mapie nie oznacza, że Google jej nie znajdzie przez linki, parametry albo zewnętrzne źródła.
Dlaczego WooCommerce tworzy tak wiele adresów?
Sklep musi umożliwiać klientowi sortowanie, filtrowanie, wyszukiwanie i wybieranie wariantów. Każda z tych funkcji może wygenerować nowy URL.
Załóżmy, że sklep ma kategorię /sklep/krzesla/. Klient może ustawić kolor czarny, materiał welur, cenę od 300 do 600 zł, sortowanie od najtańszych i widok drugiej strony wyników. W zależności od użytych wtyczek mogą powstać adresy:
/sklep/krzesla/?filter_kolor=czarny
/sklep/krzesla/?filter_material=welur
/sklep/krzesla/?min_price=300&max_price=600
/sklep/krzesla/?orderby=price
/sklep/krzesla/page/2/
/sklep/krzesla/?filter_kolor=czarny&filter_material=welurPrzy kilku filtrach liczba możliwych kombinacji rośnie bardzo szybko. Jeżeli sklep ma 10 kolorów, 8 materiałów, 20 marek, 6 zakresów cenowych i kilka opcji sortowania, nie oznacza to kilkudziesięciu adresów — po połączeniu wartości mogą powstać tysiące albo dziesiątki tysięcy wariantów. Większość z nich nie ma własnej wartości dla użytkownika Google: pokazuje niemal te same produkty w innej kolejności albo bardzo wąski, przypadkowy zestaw.
Co powinno zostać w indeksie Google?
Strona główna powinna być indeksowana i posiadać canonical wskazujący na swój podstawowy adres. Sprawdź, czy nie działają równolegle wersje:
http://sklep.pl/
https://sklep.pl/
https://www.sklep.pl/
https://sklep.pl/index.phpWszystkie dodatkowe warianty powinny prowadzić do jednej wybranej wersji.
Główne kategorie produktowe odpowiadają na szerokie zapytania zakupowe (kremy do twarzy, komody do salonu, biurka elektryczne, lampy wiszące, buty do biegania) i są zwykle najważniejszymi stronami SEO w sklepie. Dobra kategoria powinna mieć konkretny H1, stabilny adres, dopasowane produkty, logiczne podkategorie, opis pomagający w wyborze, linkowanie do powiązanych grup, własny title i meta description oraz self-canonical (strona wskazuje samą siebie jako wersję podstawową). Sposób planowania struktury rozwijamy w poradniku kategorie w sklepie WooCommerce — architektura pod SEO.
Podkategorie z własną intencją powinny pozostać w indeksie, jeżeli opisują realną grupę produktów i odpowiadają na osobne zapytanie — np. kosmetyki do twarzy → kremy do twarzy → kremy do cery suchej → kremy z filtrem SPF 50. Nie warto natomiast indeksować kilku stron oznaczających prawie to samo (kremy do suchej skóry, kremy dla cery suchej, kremy mocno nawilżające, pielęgnacja skóry suchej) — jeżeli zawierają podobne produkty i nie mają wyraźnie różnych celów, lepiej połączyć je w jedną mocniejszą stronę.
Karty produktów powinny być indeksowane, gdy można je kupić, odpowiadają na zapytania o konkretny model, mają unikalne informacje, zawierają prawidłową cenę i dostępność, są połączone z właściwymi kategoriami i nie są technicznym duplikatem innego wariantu. Karta produktu może rankować na zapytanie „Biurko Varius 120 × 65 cm dąb naturalny", a kategoria odpowiada na szerszą frazę „biurka elektryczne" — obie strony są potrzebne, ale nie powinny walczyć o dokładnie tę samą intencję.
Produkty chwilowo niedostępne. Chwilowy brak magazynowy zwykle nie jest powodem do usunięcia produktu z Google. Jeżeli produkt ma wrócić, zachowaj jego adres, kod odpowiedzi 200, opis i opinie; pokaż informację o braku, możliwość powiadomienia oraz podobne produkty. Pełny podział decyzji dla produktu, który wróci, ma następcę albo został wycofany na stałe, znajduje się w sekcji „Co zrobić z produktem wycofanym ze sprzedaży?".
Wybrane strony marek mogą pozostać w indeksie, jeżeli zawierają sensowną liczbę produktów, marka jest wyszukiwana, strona ma własny H1 i opis, różni się od ogólnej kategorii i prowadzą do niej linki wewnętrzne (np. /marka/bosch/, /marka/cerave/, /marka/nowodvorski/). Archiwum marki z jednym wycofanym produktem i bez własnej treści zwykle nie wnosi wartości.
Kontrolowane landing page z filtrów. Niektóre cechy produktów mają realny popyt: czarne krzesła tapicerowane, biurka elektryczne 120 cm, serum z retinolem, materace 160 × 200 cm, białe komody 150 cm. Taki temat można przygotować jako osobną stronę SEO ze stałym, czytelnym URL-em, własnym H1, unikalnym title i description, dopasowanymi produktami, treścią pomocniczą, self-canonicalem, linkami z kategorii/menu/poradników oraz miejscem w sitemapie. Ten artykuł odpowiada na pytanie, czy dany typ strony filtrowania powinien być indeksowany. Pełna logika wyboru wartościowych kombinacji, kontrolowania faset i technicznej konfiguracji filtrów znajduje się w poradniku nawigacja fasetowa i filtry WooCommerce — SEO bez duplikatów.
Wpisy blogowe i poradniki mogą pozyskiwać ruch informacyjny i wspierać kategorie — artykuł „Jak wybrać materac?" prowadzi do kategorii materacy, poradnik o witaminie C linkuje do serum i kremów. Wpis powinien być indeksowany, jeżeli odpowiada na konkretne pytanie, nie kopiuje opisu kategorii, zawiera użyteczną treść i wspiera właściwe strony sprzedażowe.
Strony informacyjne budujące zaufanie — o firmie, kontakt, dostawa, zwroty, gwarancja, realizacje, salony stacjonarne, obsługiwane lokalizacje — mogą pozostać w indeksie. Nie każda z nich będzie zdobywać duży ruch, ale pomaga użytkownikowi i wyszukiwarce zrozumieć firmę.
Co zwykle powinno być poza indeksem?
Koszyk (/koszyk/, /cart/, ?add-to-cart=123) jest stroną operacyjną — jego zawartość zależy od konkretnego użytkownika i nie powinna pojawiać się w wynikach Google. Zwykle stosuje się noindex, wyłączenie z sitemapy i brak linkowania z treści SEO poza elementami interfejsu. Parametr ?add-to-cart= nie powinien być traktowany jako osobna strona produktu.
Checkout (/zamowienie/, /checkout/, /order-pay/) służy do finalizacji zakupu — nie jest stroną docelową dla ruchu z wyszukiwarki. Powinien mieć noindex, brak obecności w sitemapie i dostępność tylko w ramach procesu zakupowego. Nie blokuj checkoutu w sposób, który uniemożliwi działanie płatności albo testowanie integracji.
Moje konto i strony logowania (/moje-konto/, /lost-password/, /edit-account/, /orders/) nie odpowiadają na publiczne zapytania, mogą wyświetlać treść zależną od zalogowanego użytkownika i nie powinny znajdować się w indeksie. Prywatnych danych nie zabezpiecza jednak noindex — jeżeli strona zawiera dane użytkownika, musi wymagać poprawnego uwierzytelnienia. noindex jest tylko instrukcją dla wyszukiwarki, a nie mechanizmem bezpieczeństwa.
Potwierdzenie zamówienia. Strona „Dziękujemy za zakup" może zawierać numer zamówienia, status płatności, podsumowanie i instrukcje dalszego postępowania — powinna być poza indeksem. Dodatkowo należy sprawdzić, czy wejście na przypadkowy adres potwierdzenia nie ujawnia danych innego klienta.
Wewnętrzne wyniki wyszukiwania (np. /?s=krzeslo&post_type=product). Wyszukiwarka sklepu może wygenerować stronę dla dowolnego wpisanego tekstu: literówek, numerów telefonu, losowych znaków, fraz niezwiązanych z ofertą albo zapytań generowanych automatycznie przez boty. Takie strony powinny być poza indeksem — najczęściej stosuje się noindex, brak w sitemapie i ograniczanie crawlowania dużej liczby parametrów dopiero po upewnieniu się, że Google odczytało wcześniejsze instrukcje.
Sortowanie produktów (?orderby=price, ?orderby=price-desc, ?orderby=popularity, ?orderby=rating). Zmiana kolejności nie tworzy nowej oferty — to nadal ta sama kategoria z tymi samymi produktami. Adresy sortowania nie powinny konkurować z podstawową kategorią. Możliwe rozwiązania: canonical do czystego adresu kategorii, noindex jeśli wymaga tego konfiguracja, sortowanie bez tworzenia indeksowalnych adresów, ograniczenie wewnętrznych linków prowadzących do parametrów. Nie ustawiaj automatycznie jednocześnie canonicala, noindex i blokady robots.txt — taki zestaw utrudnia interpretację konfiguracji i jej późniejsze testowanie.
Większość kombinacji filtrów. W tym artykule filtry są jednym z wielu typów adresów i interesuje nas przede wszystkim decyzja: index czy noindex. Domyślnie kombinacje filtrów powinny być traktowane jako narzędzie dla klienta, a nie osobne landing page SEO:
?filter_color=black
?filter_color=black&filter_material=velvet
?min_price=273&max_price=418
?filter_brand=x&orderby=priceNajczęściej takie adresy nie trafiają do sitemapy, otrzymują noindex, nie są masowo linkowane zwykłymi linkami HTML, mają ograniczane crawlowanie po zaplanowaniu całej architektury i są zastępowane kontrolowanymi landing page, jeśli kombinacja ma potencjał SEO. Szczegółowy sposób wyboru faset, oceny popytu i wdrożenia reguł opisujemy w artykule nawigacja fasetowa i filtry WooCommerce — SEO bez duplikatów.
Cienkie tagi produktów. Tagi WooCommerce często powstają bez planu (promocja, nowość, polecane, bestseller, 2026, kolekcja lato, modny). Jeżeli każdy tag tworzy własne archiwum, sklep może mieć setki stron z kilkoma produktami i bez własnej wartości. Tag pozostaw w indeksie tylko wtedy, gdy jest zarządzany jak pełnoprawna strona: ma własną intencję, odpowiednio dużo produktów, unikalną treść, jest stabilny i prowadzą do niego linki. W przeciwnym razie zastosuj noindex albo zrezygnuj z publicznego archiwum.
Archiwa autora i daty. W sklepie prowadzonym przez jedną osobę archiwum autora może zawierać dokładnie te same wpisy co blog. Podobny problem dotyczy archiwów roku, miesiąca i dnia. Jeżeli nie pomagają użytkownikowi i tylko powielają listę treści, zwykle warto oznaczyć je jako noindex.
Strony załączników WordPressa. WordPress może tworzyć osobną stronę dla każdego zdjęcia lub pliku (np. /nazwa-produktu/zdjecie-produktu/). Jeżeli taka strona zawiera tylko jedno zdjęcie i nazwę pliku, nie ma wartości jako osobny wynik — najczęściej lepiej przekierować ją do właściwego produktu albo pliku, albo wyłączyć strony załączników z indeksacji.
Listy życzeń i porównywarki (/wishlist/, /compare/) są funkcjonalnością użytkownika, a nie stroną SEO. Zwykle powinny być poza indeksem, poza sitemapą i odpowiednio zabezpieczone, jeśli zawierają dane konta.
Puste i automatyczne archiwa. Strona bez produktów, treści i jasnego celu nie powinna pozostawać w indeksie tylko dlatego, że WooCommerce utworzył ją automatycznie. Dotyczy to m.in. pustych kategorii, nieużywanych atrybutów, starych kolekcji, testowych producentów i kategorii „Bez kategorii". Najpierw ustal, czy strona będzie uzupełniona; jeśli nie, usuń ją, połącz z inną albo zastosuj właściwy kod odpowiedzi.
Tabela: co indeksować, a co blokować?
| Typ strony | Domyślna decyzja | Najczęstszy mechanizm |
|---|---|---|
| Strona główna | Indeksować | Index, self-canonical |
| Główna kategoria | Indeksować | Index, self-canonical |
| Wartościowa podkategoria | Indeksować | Index, self-canonical |
| Produkt dostępny | Indeksować | Index, self-canonical |
| Produkt chwilowo niedostępny | Zwykle indeksować | Kod 200, aktualna dostępność |
| Produkt usunięty z następcą | Nie zachowywać starej strony | 301 do odpowiednika |
| Produkt usunięty bez odpowiednika | Usunąć | 404 albo 410 |
| Wartościowa strona marki | Indeksować | Index, self-canonical |
| Pusta strona marki | Nie indeksować | Noindex albo usunięcie |
| Kontrolowany landing filtra | Indeksować | Index, unikalny URL i treść |
| Przypadkowa kombinacja filtrów | Nie indeksować | Noindex, zarządzanie crawlem |
| Sortowanie | Nie indeksować osobno | Canonical do kategorii lub noindex |
| Paginacja | Zostawić crawl | Unikalny URL, zwykle self-canonical |
| Wyszukiwarka wewnętrzna | Nie indeksować | Noindex |
| Koszyk | Nie indeksować | Noindex |
| Checkout | Nie indeksować | Noindex |
| Konto klienta | Nie indeksować | Noindex i uwierzytelnienie |
| Potwierdzenie zamówienia | Nie indeksować | Noindex |
| Tag produktu | Zwykle nie indeksować | Noindex |
| Archiwum autora lub daty | Zwykle nie indeksować | Noindex |
Parametry UTM i gclid | Nie indeksować osobno | Canonical do czystego URL |
| Strona załącznika | Zwykle nie indeksować | Przekierowanie albo noindex |
| Regulamin i polityka prywatności | Zależnie od strategii | Często noindex, bez sitemapy |
| Wartościowy poradnik | Indeksować | Index, self-canonical |
| Staging i wersja testowa | Nie udostępniać publicznie | Hasło, ograniczenie dostępu |
Tabela jest punktem wyjścia. Sklep B2B, marketplace, konfigurator albo serwis z tysiącami wariantów może wymagać innej polityki.
Paginacja — blokować czy zostawić?
Paginacji nie należy automatycznie blokować, ponieważ może być jedyną drogą Google do produktów znajdujących się na dalszych stronach kategorii (np. /krzesla/page/2/, /krzesla/page/3/).
Dobre rozwiązanie powinno zapewniać osobny URL dla każdej strony, zwykłe linki HTML do kolejnych stron, self-canonical na poszczególnych stronach, możliwość przejścia robota do produktów oraz brak canonicala wszystkich stron do strony pierwszej. Strona druga pokazuje inne produkty niż strona pierwsza — nie jest więc pełnym duplikatem. Nie musi natomiast znajdować się w sitemapie; sitemap powinna przede wszystkim zawierać główną kategorię i strony produktów.
Infinite scroll i przycisk „Załaduj więcej". Googlebot nie zachowuje się dokładnie jak klient — nie należy zakładać, że kliknie przycisk i automatycznie załaduje dalsze produkty. Jeżeli korzystasz z nieskończonego przewijania, przycisku „Pokaż więcej" albo dynamicznego ładowania AJAX, zadbaj, aby produkty były dostępne również pod zwykłymi adresami paginacji połączonymi linkami <a href>. W przeciwnym razie Google może widzieć tylko pierwszą część kategorii.
Warianty produktów — jedna strona czy osobne adresy?
Decyzja zależy od tego, czy warianty odpowiadają na osobne zapytania i czy są realnie różnymi ofertami.
Jeden URL dla wariantów najczęściej sprawdza się, gdy produkt różni się jedynie rozmiarem, prostym kolorem, niewielkim parametrem albo liczbą sztuk w opakowaniu (np. /koszulka-basic/, gdzie klient wybiera kolor i rozmiar). Korzyści: jedna mocna karta, wspólne opinie, mniej duplikatów, prostsze zarządzanie.
Osobne URL-e dla wariantów mogą mieć sens, gdy każdy wariant ma własny popyt, osobne zdjęcia, istotnie inną specyfikację, własne SKU i stan, może być samodzielną stroną docelową i jest prezentowany jako osobna oferta w reklamach oraz feedzie (np. telefon 256 GB i 512 GB, materac 160 × 200 cm i 180 × 200 cm). Osobne strony powinny mieć stabilne adresy, jednoznaczną treść, poprawne canonicale, spójne dane produktowe i przemyślane linkowanie pomiędzy wariantami. Nie indeksuj osobno 40 wariantów, jeśli każdy pokazuje ten sam opis i różni się tylko jednym słowem w nazwie.
Co zrobić z produktem wycofanym ze sprzedaży?
Nie stosuj noindex jako uniwersalnej odpowiedzi na każdy niedostępny albo usunięty produkt.
Produkt wróci do sprzedaży: zostaw ten sam adres, kod 200, opis, opinie, podobne produkty i możliwość powiadomienia. Nie usuwaj produktu z indeksu przy każdej krótkiej zmianie stanu magazynowego.
Jest nowa wersja produktu: ustaw przekierowanie 301 na bezpośredniego następcę (np. /model-x-2024/ → /model-x-2026/).
Brak następcy, ale istnieje sensowna kategoria: możesz przekierować do kategorii, jeżeli rzeczywiście pomaga klientowi znaleźć bardzo podobne produkty. Nie rób tego automatycznie dla całego katalogu.
Nie ma odpowiednika: pozostaw poprawny błąd 404 albo 410. Nie przekierowuj każdego usuniętego produktu na stronę główną. Szczegółowe zasady opisujemy w poradniku przekierowania 301 i błędy 404 w sklepie WooCommerce.
Noindex, canonical, robots.txt, 301 czy 404?
Każdy mechanizm rozwiązuje inny problem.
noindex mówi wyszukiwarce: „możesz odwiedzić tę stronę, ale nie pokazuj jej w wynikach".
<meta name="robots" content="noindex, follow">Stosuj go m.in. dla koszyka, checkoutu, wyników wyszukiwania, konta, przypadkowych archiwów i technicznych wyników filtrów. Aby Google zobaczyło noindex, musi móc odwiedzić stronę.
Canonical wskazuje preferowany adres spośród kilku identycznych albo bardzo podobnych wersji.
<link rel="canonical" href="https://sklep.pl/krzesla/">Może być przydatny dla sortowania, parametrów śledzących, technicznych wariantów URL i duplikatów tej samej strony. Canonical jest wskazówką, a nie bezwzględnym poleceniem — Google może wybrać inny adres, jeśli pozostałe sygnały są sprzeczne. Dlatego spójne powinny być canonical, linki wewnętrzne, sitemap, przekierowania, wersja HTTPS, hreflang i dane strukturalne.
robots.txt określa, których adresów robot nie powinien pobierać. Może ograniczyć marnowanie zasobów na nieskończone kombinacje parametrów, techniczne endpointy i niepotrzebne ścieżki zaplecza. Nie gwarantuje jednak usunięcia adresu z wyników — Google może znać URL z linków i wyświetlić go bez opisu, mimo że nie pobrało treści. Nie używaj robots.txt jako zamiennika noindex.
Przekierowanie 301 oznacza stałe przeniesienie strony. Używaj, gdy zmienił się slug, połączono dwie kategorie, produkt ma nowy odpowiednik, zmieniła się struktura adresów albo strona została przeniesiona. Cel przekierowania musi być tematycznie zbliżony.
404 i 410. Kod 404 oznacza, że strony nie znaleziono; kod 410 mówi, że została trwale usunięta. Są poprawne, gdy nie istnieje następca, adres powstał przez błąd, strona nie ma wartości albo nie ma sensownego celu przekierowania. Pojedynczy 404 nie jest katastrofą SEO — problemem są martwe linki wewnętrzne, utrata wartościowych adresów i duża liczba błędów wynikająca z niekontrolowanej zmiany struktury.
noindex i robots.txt nie zabezpieczają prywatnych treści
Danych klientów, dokumentów B2B i paneli partnerów nie zabezpiecza się przez robots.txt ani noindex — wymagają one logowania, odpowiednich uprawnień i zabezpieczenia po stronie serwera. Znaczniki dla wyszukiwarki to instrukcje widoczności, a nie mechanizm kontroli dostępu.
Dlaczego nie warto stosować wszystkich mechanizmów naraz?
Problemem nie jest sama liczba ustawień, lecz wysyłanie sprzecznych sygnałów. Przykład złej konfiguracji: strona ma noindex, canonical wskazuje kategorię, adres jest zablokowany w robots.txt i jednocześnie znajduje się w sitemapie. Google otrzymuje wtedy naraz informacje: nie indeksuj, traktuj jako duplikat, nie odwiedzaj oraz „adres jest na tyle ważny, że umieszczono go w mapie". Zamiast tego wybierz rozwiązanie odpowiadające głównemu problemowi:
| Problem | Właściwe pytanie | Typowe rozwiązanie |
|---|---|---|
| Strona nie ma pojawiać się w Google | Czy ma nadal działać dla klienta? | noindex |
| Strona jest duplikatem | Który URL ma być główny? | Canonical |
| Strona została przeniesiona | Jaki jest jej następca? | 301 |
| Strona została usunięta | Czy istnieje sensowny odpowiednik? | 404, 410 albo 301 |
| Robot traci czas na nieskończone parametry | Czy adres musi być crawlowany? | Zarządzanie linkami i robots.txt |
| Treść jest prywatna | Kto może ją zobaczyć? | Logowanie i uprawnienia |
Jak powinna wyglądać mapa strony XML?
Sitemap powinna zawierać adresy, które chcesz indeksować, a nie pełną listę wszystkiego, co technicznie istnieje.
W mapie powinny znaleźć się strona główna, indeksowalne kategorie i podkategorie, produkty, wartościowe strony marek, landing page SEO, poradniki oraz ważne strony informacyjne. Nie powinny znajdować się adresy noindex, przekierowania, błędy 404 i 410, koszyk, checkout, konto, wyniki wyszukiwania, sortowanie, losowe filtry, niekanoniczne duplikaty ani wersje robocze. Każdy adres w sitemapie powinien zwracać kod 200, być indeksowalny, posiadać canonical wskazujący na siebie i prezentować właściwą treść.
Przy większym sklepie warto rozdzielić mapy na produkty, kategorie, wpisy, strony oraz marki lub inne kontrolowane taksonomie — ułatwia to ustalenie, którego typu strony Google nie indeksuje prawidłowo.
Parametr lastmod. Data ostatniej modyfikacji powinna zmieniać się po istotnej aktualizacji strony (zmianie opisu, dodaniu ważnych parametrów, aktualizacji oferty, przebudowie treści). Nie powinna aktualizować się przy każdym wejściu użytkownika albo drobnej zmianie technicznej niezwiązanej z zawartością.
Linkowanie wewnętrzne a indeksacja
Google łatwiej rozpoznaje ważne strony, gdy prowadzą do nich zwykłe i logiczne linki.
Najważniejsze kategorie powinny być dostępne przez menu, stronę główną, kategorie nadrzędne, breadcrumbs, poradniki i sekcje powiązanych kategorii. Produkty powinny otrzymywać linki z kategorii, wyników wewnętrznych, rekomendacji, artykułów i list bestsellerów. Jeżeli produkt znajduje się tylko na 15. stronie paginacji i nigdzie indziej nie jest podlinkowany, może być odwiedzany rzadziej.
Strony osierocone. Strona osierocona ma poprawny URL i może znajdować się w sitemapie, ale nie prowadzi do niej żaden link wewnętrzny. Google może ją znaleźć, jednak struktura sklepu nie pokazuje, że jest ważna. Typowe strony osierocone to stare produkty, niepodlinkowane kategorie, landing page kampanii, wpisy po zmianie menu i strony marek utworzone przez import. Sitemap nie zastępuje dobrej nawigacji.
Jak sprawdzić indeksację sklepu w Google Search Console?
Raport „Indeksowanie stron" pokazuje adresy zaindeksowane, wykluczone, zablokowane, przekierowane, nieznalezione i uznane za duplikaty. Nie każda pozycja w sekcji „Nie zindeksowano" jest błędem — jeżeli znajdują się tam koszyk, filtry, przekierowania i tagi noindex, raport może potwierdzać, że konfiguracja działa prawidłowo. Problem zaczyna się wtedy, gdy Google wyklucza główną kategorię, ważny produkt, stronę marki albo poradnik generujący sprzedaż.
„Strona wykryta — obecnie niezindeksowana". Google zna adres, ale jeszcze go nie odwiedziło albo nie uznało za wystarczająco ważny. Możliwe przyczyny: słabe linkowanie, duża liczba niepotrzebnych URL-i, nowa strona, niski priorytet w architekturze, problemy serwera, przeciążenie sklepu.
„Strona zeskanowana — obecnie niezindeksowana". Google odwiedziło stronę, ale nie dodało jej do indeksu. Możliwe przyczyny: cienka treść, podobieństwo do innych stron, pusta kategoria, mało produktów, brak wartości względem już indeksowanej strony, soft 404, niska jakość techniczna lub treściowa. Nie rozwiązuj tego przez wielokrotne klikanie „Poproś o zindeksowanie" — najpierw popraw samą stronę i jej miejsce w strukturze.
„Duplikat — Google wybrał inną stronę kanoniczną". Google uznało, że inny adres lepiej reprezentuje tę treść. Sprawdź canonical, sitemapę, linkowanie wewnętrzne, przekierowania, wersje z parametrami, HTTP i HTTPS oraz www i bez www.
„Alternatywna strona z prawidłowym tagiem kanonicznym". Może być poprawnym stanem, jeżeli adres jest technicznym duplikatem i wskazuje właściwą wersję. Nie próbuj indeksować każdego URL-a widocznego w raporcie.
„Wykluczono przez tag noindex". To prawidłowy wynik dla koszyka i checkoutu. Jest problemem, jeśli dotyczy strony, która ma zdobywać ruch.
„Zablokowano przez robots.txt". Sprawdź, czy blokada była zamierzona. Jeżeli adres jednocześnie ma noindex, Google może nie mieć możliwości odczytania tej instrukcji.
„Miękki błąd 404". Strona technicznie zwraca kod 200, ale wygląda jak usunięta lub pusta (kategoria bez produktów, produkt z komunikatem „nie znaleziono", pusta strona wyniku, filtr bez dostępnych produktów). Taka strona powinna zostać uzupełniona, przekierowana albo zwracać właściwy kod błędu.
Czy komenda site: pokazuje liczbę stron w indeksie?
Komenda site:twojsklep.pl jest przydatna do szybkiego podglądu. Możesz sprawdzić, czy pojawiają się koszyk, konto, filtry, sortowania, stare subdomeny, wersje testowe albo nieaktualne produkty. Nie traktuj jednak liczby wyników jako dokładnego raportu indeksacji — do analizy wykorzystuj przede wszystkim raport stron w Search Console, inspekcję URL, sitemapę, crawl sklepu i logi serwera.
Jak zaplanować politykę indeksacji krok po kroku?
Krok 1. Zbierz wszystkie typy adresów. Nie ograniczaj się do adresów z sitemapy — zbierz URL-e z crawla, Search Console, Google Analytics, sitemapy, logów serwera, linków zewnętrznych, parametrów generowanych przez filtry i panelu WooCommerce.
Krok 2. Pogrupuj adresy: produkty, kategorie, marki, filtry, sortowania, paginacja, wyszukiwarka, tagi, koszyk i checkout, blog, strony prawne, stare URL-e, załączniki.
Krok 3. Określ rolę każdej grupy. Dla każdego typu zapytaj: czy użytkownik może chcieć trafić tu bezpośrednio z Google, czy strona ma własną intencję, czy treść różni się od innych adresów, czy strona jest stabilna, czy ma wystarczającą ofertę, czy można ją sensownie podlinkować i czy powinna znaleźć się w sitemapie.
Krok 4. Wybierz mechanizm. Najpierw przypisz adresom index, noindex, canonical, 301, 404 lub 410, ograniczenie crawlu albo autoryzację. Nie zaczynaj od przypadkowego dopisywania reguł w robots.txt.
Krok 5. Wdróż na środowisku testowym. Sprawdź kod strony, nagłówki HTTP, canonical, status odpowiedzi, sitemapę, linki, zachowanie filtrów i wersję mobilną.
Krok 6. Wykonaj crawl kontrolny. Crawler powinien pokazać indeksowalne URL-e, strony noindex, canonicale, przekierowania, błędy, duplikaty, strony osierocone i głębokość linkowania. Ten artykuł szczegółowo omawia indeksację; jeżeli potrzebujesz szerszego przeglądu pozostałych elementów — szybkości, danych strukturalnych, hreflangów, błędów odpowiedzi i konfiguracji technicznej — skorzystaj również z checklisty technicznego SEO WooCommerce.
Krok 7. Monitoruj po wdrożeniu. Po zmianie obserwuj liczbę stron indeksowanych, adresy wykluczone, ruch kategorii i produktów, błędy serwera, częstotliwość crawlowania i wybór canonicali przez Google. Przy dużym sklepie efekty porządkowania indeksacji nie muszą pojawić się od razu — Google musi ponownie odwiedzić i przetworzyć istniejące adresy.
Najczęstsze błędy indeksacji WooCommerce
Najwięcej szkody robią: blokada w robots.txt zamiast noindex, przypadkowy noindex na kategorii, indeksowanie wszystkich filtrów i canonical paginacji do strony pierwszej.
- 1. Blokowanie w
robots.txtzamiast użycianoindex— Google nie może wejść na stronę i odczytać instrukcji, że ma ją usunąć z indeksu. - 2.
noindexna ważnej kategorii — jedna zmiana w ustawieniach wtyczki SEO może wyłączyć z Google całą taksonomię produktów. - 3. Indeksowanie wszystkich filtrów — sklep z kilkuset produktami generuje dziesiątki tysięcy podobnych stron.
- 4. Canonical całej paginacji do strony pierwszej — Google dostaje sygnał, że kolejne strony są duplikatami, mimo że zawierają inne produkty.
- 5.
noindexna produkcie chwilowo niedostępnym — produkt wraca do sprzedaży, ale wcześniej został usunięty z indeksu i musi ponownie budować widoczność. - 6. Wszystkie adresy w sitemapie — mapa zawiera filtry, przekierowania, błędy i strony
noindex, przez co wysyła sprzeczne sygnały. - 7. Zmiana adresów bez przekierowań — stare produkty i kategorie zaczynają zwracać 404, mimo że istnieją pod nowymi URL-ami.
- 8. Brak spójności między canonicalem, sitemapą i linkami — canonical wskazuje adres A, sitemap zawiera B, a menu prowadzi do C.
Co możesz sprawdzić samodzielnie?
Większość problemów z indeksacją można wstępnie zdiagnozować bez specjalistycznych narzędzi.
- Wpisz
site:twojsklep.pli sprawdź, czy w wynikach pojawiają się koszyk, konto, filtry albo wersja testowa. - Otwórz źródło koszyka i checkoutu. Sprawdź, czy zawierają
noindex. - Otwórz kategorię z parametrem
?orderby=pricei sprawdź, jaki adres wskazuje canonical. - Przetestuj pojedynczy filtr i kombinację kilku filtrów. Sprawdź, czy trafiają do sitemapy albo wyników Google.
- Otwórz sitemapę i poszukaj stron
noindex, przekierowań, filtrów oraz błędów. - Sprawdź, czy kolejne strony paginacji mają osobne URL-e i zwykłe linki.
- Zweryfikuj, czy środowisko testowe wymaga hasła albo jest ograniczone po stronie serwera.
- Zapisz decyzję index/noindex/canonical/301/404 dla każdego typu adresu przed zmianą ustawień.
Kiedy warto zlecić to specjaliście?
Pomoc specjalisty ma sens, gdy liczba wykrytych adresów wielokrotnie przekracza liczbę produktów, Google wybiera inne canonicale niż sklep albo ważne kategorie nie trafiają do indeksu.
Rozważ wsparcie, gdy sklep ma tysiące produktów, liczba wykrytych adresów wielokrotnie przekracza liczbę produktów i kategorii, filtry tworzą nieskończone kombinacje, Google wybiera inne canonicale niż sklep, ważne kategorie mają status „zeskanowano, ale nie zindeksowano", sitemap zawiera błędne adresy, wiele produktów jest osieroconych, po migracji spadła liczba indeksowanych stron, sklep używa kilku wtyczek SEO, działa kilka wersji językowych, wdrożono niestandardową paginację albo infinite scroll, albo zmiany muszą zostać wykonane programistycznie.
Przy większym sklepie nie wystarczy zaznaczyć jednego pola „noindex filtry". Trzeba połączyć strukturę kategorii, dane o frazach, ruch i sprzedaż, crawl, Search Console, canonicale, sitemapę, linkowanie i logi Googlebota. W ramach SEO technicznego można ustalić, które strony powinny być indeksowane, przygotować reguły dla parametrów oraz sprawdzić efekt po wdrożeniu. Jeżeli problem obejmuje również treści, kategorie, kanibalizację i widoczność całego sklepu, właściwym punktem wyjścia może być audyt SEO sklepu.
Najczęściej zadawane pytania
Czy koszyk i checkout powinny być indeksowane?
Nie. Są to strony operacyjne zależne od koszyka konkretnego użytkownika. Powinny mieć noindex i nie powinny znajdować się w sitemapie.
Czy należy blokować wszystkie filtry WooCommerce?
Nie. Większość przypadkowych kombinacji powinna być poza indeksem, ale wybrane filtry odpowiadające na realne zapytania można przygotować jako osobne landing page SEO.
Czy robots.txt usuwa stronę z Google?
Nie gwarantuje tego. robots.txt ogranicza crawlowanie. Aby usunąć stronę z wyników, Google powinno zobaczyć noindex , przekierowanie albo odpowiedni kod błędu.
Czy strony paginacji powinny mieć noindex?
Nie należy robić tego automatycznie. Strony paginacji pomagają Google dotrzeć do dalszych produktów. Powinny mieć unikalne URL-e, zwykłe linki i najczęściej self-canonical.
Co zrobić z produktem chwilowo niedostępnym?
Pozostaw adres z kodem 200, zachowaj opis oraz opinie i pokaż informację o braku. Możesz dodać powiadomienie o dostępności i podobne produkty.
Co zrobić z produktem wycofanym na stałe?
Jeśli ma bezpośredniego następcę, ustaw przekierowanie 301. Jeżeli nie ma dobrego odpowiednika, zastosuj 404 albo 410 zamiast przekierowania na stronę główną.
Czy tagi produktów warto indeksować?
Zwykle nie. Wyjątkiem są tagi zaplanowane jako wartościowe strony z własną intencją, treścią i odpowiednią liczbą produktów.
Co powinno znaleźć się w sitemapie WooCommerce?
Tylko adresy indeksowalne, kanoniczne i zwracające kod 200: produkty, kategorie, wartościowe marki, landing page, poradniki i ważne strony informacyjne.
Trzy grupy adresów, jeden mechanizm na problem
Dobra indeksacja WooCommerce polega na rozdzieleniu adresów na trzy grupy:
- strony, które mają zdobywać ruch — kategorie, produkty, marki, landing page i poradniki,
- strony potrzebne klientowi, ale nie Google — koszyk, konto, checkout, wyszukiwarka i filtry techniczne,
- adresy przeniesione albo usunięte — obsługiwane przez 301, 404 lub 410.
Następnie trzeba zastosować jeden mechanizm odpowiadający konkretnemu problemowi i zachować spójność między kodem strony, sitemapą, canonicalami oraz linkowaniem wewnętrznym.
Jeżeli chcesz sprawdzić, czy Google indeksuje właściwe części Twojego sklepu, możemy przeanalizować kategorie, produkty, filtry, canonicale, sitemapę oraz raporty Search Console. W ramach SEO technicznego WooCommerce przygotujemy mapę decyzji i wskażemy konkretne reguły do wdrożenia — bez blokowania stron, które powinny pracować na sprzedaż.