WooCommerce Store Indexing — what to block and what to keep in Google

A store has 2,000 products, but Google Search Console detects 80,000 URLs. Sorting pages, empty tags, the cart and random filter combinations show up in the results. At the same time, some important categories and products never make it into the index.
This is a typical problem for WooCommerce stores. A single product can be reachable through a category, the search box, a filter, a campaign parameter, a variant and several kinds of sorting. For the customer these are just different ways of browsing the same offer. For Google they can be separate URLs that have to be visited and assessed.
The point is not to block as many pages as possible. Settings that are too aggressive can remove important categories from Google, cut off the robot's path to products, or stop the search engine from ever seeing the noindex tag.
In this guide we show which WooCommerce pages should be indexed, which ones are usually worth excluding from Google, and when to use noindex, a canonical, robots.txt, a 301 redirect or a 404 error.
In short
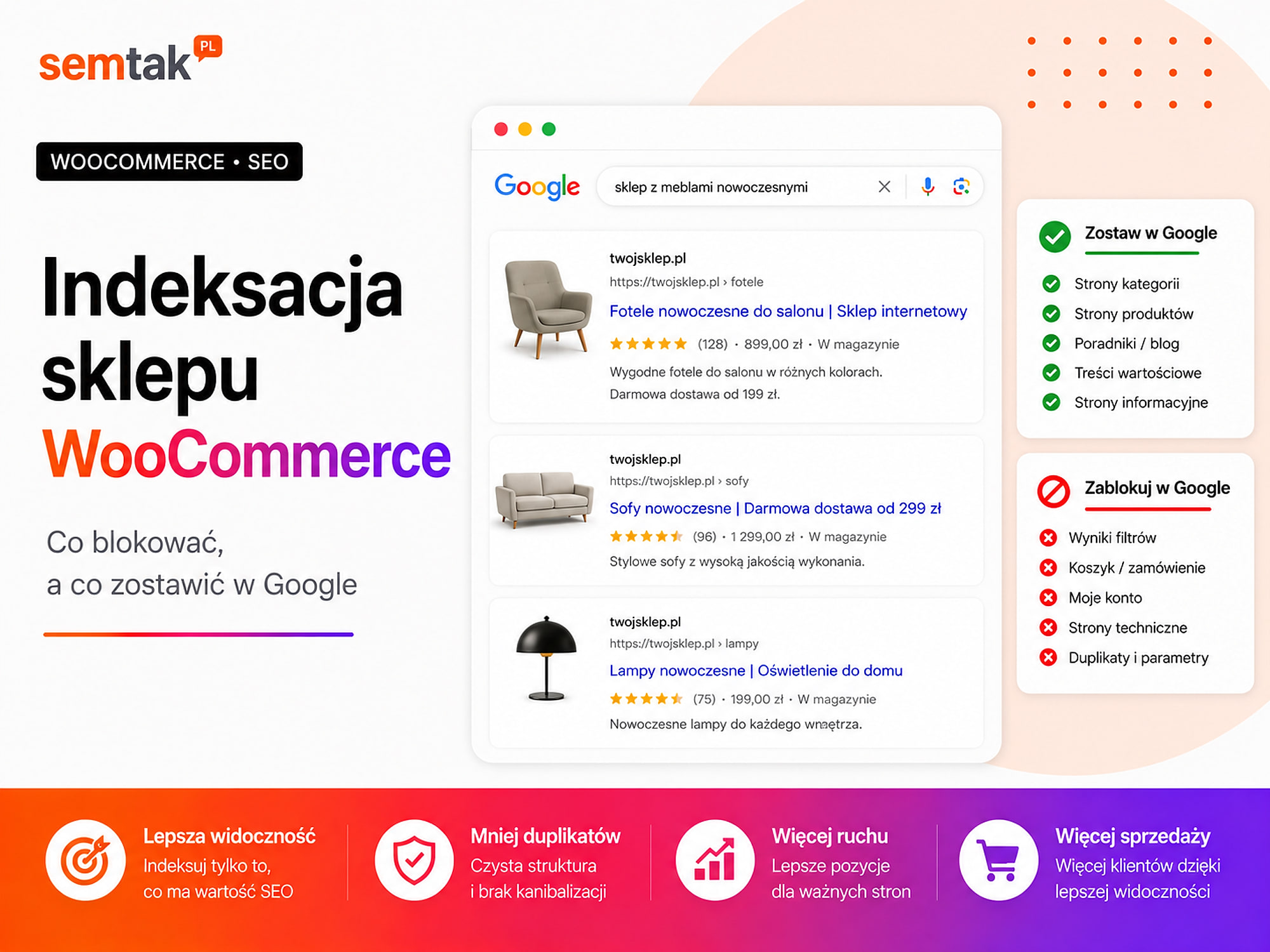
The Google index should mainly contain: the homepage, important categories and subcategories, products that are available or may return to sale, selected brand pages, purpose-built landing pages that answer real queries, and guides and other valuable content.
The following should usually stay out of the index: the cart, checkout, customer account, order confirmation, internal search results, sorting URLs, most filter combinations, thin tags and automatic archives, plus private and technical user pages.
Don't block everything in robots.txt. That tool limits how robots visit URLs, but it isn't meant for removing pages from the results. If Google is to see noindex or a canonical, it must be able to enter the page.
TL;DR
- Indexing means Google can store a page in its database and show it in the results.
- Categories, valuable products, prepared brand pages and guides should be available for indexing.
- The cart, checkout, customer account, internal search and random filters should usually have
noindex. robots.txtcontrols crawling,noindexcontrols indexing, the canonical points to the preferred version, and a 301 moves a URL permanently.- Don't combine several mechanisms automatically at once. First decide whether a page is a duplicate, has been removed, or simply shouldn't appear in Google.
- Don't block pagination without analysis. Google needs ordinary links to the next pages in order to reach products located deeper.
- A temporarily unavailable product should usually stay at the same URL and return a 200 status code.
- The XML sitemap should only contain URLs that are meant to be indexed and return a 200 code.
- The
site:command only gives a quick preview. Base more precise decisions on Search Console, a crawl and server logs.
How does crawling differ from indexing?
Google first has to find and visit a page before it can decide whether to add it to the index. The process can be simplified into four stages:
- Discovering the URL — Google finds the URL in a link, the sitemap or on another page.
- Crawl — the robot downloads the page's code.
- Rendering and analysis — Google reads the content, links, canonical, structured data and robots settings.
- Indexing — the search engine decides whether the page should be in the index and under which URL.
So a page can be known to Google but not yet visited, be visited but not indexed, end up in the index, be treated as a duplicate of another page, be excluded by noindex, or disappear after a redirect or removal. Simply adding a URL to the sitemap does not guarantee indexing. Conversely, a page missing from the sitemap doesn't mean Google won't find it through links, parameters or external sources.
Why does WooCommerce create so many URLs?
A store has to let the customer sort, filter, search and choose variants. Each of these functions can generate a new URL.
Let's say the store has a category /shop/chairs/. The customer can set the colour to black, the material to velvet, the price from 300 to 600, sorting from cheapest first, and view the second page of results. Depending on the plugins used, this can create URLs such as:
/shop/chairs/?filter_colour=black
/shop/chairs/?filter_material=velvet
/shop/chairs/?min_price=300&max_price=600
/shop/chairs/?orderby=price
/shop/chairs/page/2/
/shop/chairs/?filter_colour=black&filter_material=velvetWith several filters, the number of possible combinations grows very quickly. If a store has 10 colours, 8 materials, 20 brands, 6 price ranges and a few sorting options, that doesn't mean a few dozen URLs — once the values are combined, thousands or tens of thousands of variants can appear. Most of them have no value of their own for a Google user: they show almost the same products in a different order, or a very narrow, random set.
What should stay in the Google index?
The homepage should be indexed and have a canonical pointing to its primary URL. Check that no parallel versions are running side by side:
http://shop.com/
https://shop.com/
https://www.shop.com/
https://shop.com/index.phpAll the extra variants should lead to one chosen version.
Main product categories answer broad shopping queries (face creams, living-room dressers, electric desks, pendant lamps, running shoes) and are usually the most important SEO pages in a store. A good category should have a specific H1, a stable URL, matching products, logical subcategories, a description that helps the user choose, links to related groups, its own title and meta description, and a self-canonical (the page points to itself as the primary version). We expand on how to plan the structure in the guide category architecture in a WooCommerce store.
Subcategories with their own intent should stay in the index if they describe a real group of products and answer a separate query — e.g. face cosmetics → face creams → creams for dry skin → SPF 50 creams. On the other hand, it's not worth indexing several pages that mean almost the same thing (creams for dry skin, creams for dry complexions, intensely moisturising creams, dry skin care) — if they contain similar products and don't have clearly different goals, it's better to merge them into one stronger page.
Product pages should be indexed when they can be bought, answer queries about a specific model, contain unique information, have a correct price and availability, are linked to the right categories, and are not a technical duplicate of another variant. A product page can rank for the query "Varius desk 120 × 65 cm natural oak", while the category answers the broader phrase "electric desks" — both pages are needed, but they shouldn't fight over exactly the same intent.
Temporarily unavailable products. A temporary stock shortage is usually not a reason to remove a product from Google. If the product is coming back, keep its URL, the 200 response code, the description and reviews; show an out-of-stock notice, a notify option and similar products. The full decision breakdown for a product that will return, has a successor or has been permanently discontinued is in the section "What to do with a product withdrawn from sale?".
Selected brand pages can stay in the index if they contain a sensible number of products, the brand is searched for, the page has its own H1 and description, differs from a general category, and has internal links pointing to it (e.g. /brand/bosch/, /brand/cerave/, /brand/nowodvorski/). A brand archive with a single discontinued product and no content of its own usually adds no value.
Controlled landing pages from filters. Some product attributes have real demand: black upholstered chairs, 120 cm electric desks, retinol serum, 160 × 200 cm mattresses, white 150 cm dressers. Such a topic can be prepared as a separate SEO page with a stable, readable URL, its own H1, a unique title and description, matching products, supporting content, a self-canonical, links from categories/menu/guides, and a place in the sitemap. This article answers the question whether a given type of filter page should be indexed. The full logic for choosing valuable combinations, controlling facets and configuring filters technically is in the guide faceted navigation and WooCommerce filters — SEO without duplicates.
Blog posts and guides can attract informational traffic and support categories — an article "How to choose a mattress?" leads to the mattress category, a guide about vitamin C links to serums and creams. A post should be indexed if it answers a specific question, doesn't copy the category description, contains useful content and supports the right sales pages.
Trust-building information pages — about us, contact, delivery, returns, warranty, case studies, physical showrooms, served locations — can stay in the index. Not all of them will earn a lot of traffic, but they help the user and the search engine understand the company.
What should usually stay out of the index?
The cart (/cart/, ?add-to-cart=123) is an operational page — its contents depend on a specific user and shouldn't appear in Google's results. You usually apply noindex, exclude it from the sitemap and avoid linking to it from SEO content beyond interface elements. The ?add-to-cart= parameter should not be treated as a separate product page.
The checkout (/checkout/, /order-pay/) is used to finalise a purchase — it isn't a destination page for search traffic. It should have noindex, no presence in the sitemap, and be accessible only within the purchase process. Don't block the checkout in a way that prevents payments from working or integrations from being tested.
My account and login pages (/my-account/, /lost-password/, /edit-account/, /orders/) don't answer public queries, may display content that depends on the logged-in user, and shouldn't be in the index. However, noindex doesn't protect private data — if a page contains user data, it must require correct authentication. noindex is only an instruction for the search engine, not a security mechanism.
Order confirmation. A "Thank you for your purchase" page may contain the order number, payment status, a summary and instructions on what to do next — it should stay out of the index. You should also check that visiting a random confirmation URL doesn't reveal another customer's data.
Internal search results (e.g. /?s=chair&post_type=product). A store's search box can generate a page for any text entered: typos, phone numbers, random characters, phrases unrelated to the offer, or queries generated automatically by bots. Such pages should stay out of the index — usually you apply noindex, keep them out of the sitemap and limit crawling of large numbers of parameters only after making sure Google has read the earlier instructions.
Product sorting (?orderby=price, ?orderby=price-desc, ?orderby=popularity, ?orderby=rating). Changing the order doesn't create a new offer — it's still the same category with the same products. Sorting URLs shouldn't compete with the base category. Possible solutions: a canonical to the clean category URL, noindex if the configuration requires it, sorting that doesn't create indexable URLs, and limiting internal links that lead to parameters. Don't automatically set a canonical, noindex and a robots.txt block all at once — such a combination makes the configuration hard to interpret and to test later.
Most filter combinations. In this article, filters are one of many URL types and we're mainly interested in the decision: index or noindex. By default, filter combinations should be treated as a tool for the customer, not as separate SEO landing pages:
?filter_color=black
?filter_color=black&filter_material=velvet
?min_price=273&max_price=418
?filter_brand=x&orderby=priceMost often such URLs don't go into the sitemap, receive noindex, aren't linked en masse with ordinary HTML links, have their crawling limited once the whole architecture is planned, and are replaced by controlled landing pages if a combination has SEO potential. The detailed approach to choosing facets, assessing demand and implementing rules is described in the article faceted navigation and WooCommerce filters — SEO without duplicates.
Thin product tags. WooCommerce tags often appear without a plan (promotion, new, recommended, bestseller, 2026, summer collection, trendy). If every tag creates its own archive, a store can end up with hundreds of pages with a handful of products and no value of their own. Keep a tag in the index only when it is managed like a full-fledged page: it has its own intent, enough products, unique content, is stable and has links pointing to it. Otherwise apply noindex or drop the public archive.
Author and date archives. In a store run by one person, the author archive may contain exactly the same posts as the blog. A similar problem affects year, month and day archives. If they don't help the user and only duplicate the content list, it's usually worth marking them as noindex.
WordPress attachment pages. WordPress can create a separate page for every image or file (e.g. /product-name/product-photo/). If such a page contains only a single image and the file name, it has no value as a separate result — it's usually better to redirect it to the relevant product or file, or to exclude attachment pages from indexing.
Wishlists and comparison tools (/wishlist/, /compare/) are user functionality, not an SEO page. They should usually stay out of the index, out of the sitemap and be properly secured if they contain account data.
Empty and automatic archives. A page with no products, no content and no clear purpose shouldn't stay in the index just because WooCommerce created it automatically. This applies to empty categories, unused attributes, old collections, test manufacturers and the "Uncategorised" category. First decide whether the page will be filled out; if not, remove it, merge it with another, or apply the right response code.
Table: what to index and what to block?
| Page type | Default decision | Most common mechanism |
|---|---|---|
| Homepage | Index | Index, self-canonical |
| Main category | Index | Index, self-canonical |
| Valuable subcategory | Index | Index, self-canonical |
| Available product | Index | Index, self-canonical |
| Temporarily unavailable product | Usually index | 200 code, current availability |
| Removed product with a successor | Don't keep the old page | 301 to the equivalent |
| Removed product without an equivalent | Remove | 404 or 410 |
| Valuable brand page | Index | Index, self-canonical |
| Empty brand page | Don't index | Noindex or removal |
| Controlled filter landing page | Index | Index, unique URL and content |
| Random filter combination | Don't index | Noindex, crawl management |
| Sorting | Don't index separately | Canonical to category or noindex |
| Pagination | Leave crawlable | Unique URL, usually self-canonical |
| Internal search | Don't index | Noindex |
| Cart | Don't index | Noindex |
| Checkout | Don't index | Noindex |
| Customer account | Don't index | Noindex and authentication |
| Order confirmation | Don't index | Noindex |
| Product tag | Usually don't index | Noindex |
| Author or date archive | Usually don't index | Noindex |
UTM and gclid parameters | Don't index separately | Canonical to the clean URL |
| Attachment page | Usually don't index | Redirect or noindex |
| Terms and privacy policy | Depends on strategy | Often noindex, no sitemap |
| Valuable guide | Index | Index, self-canonical |
| Staging and test version | Don't make public | Password, restricted access |
The table is a starting point. A B2B store, a marketplace, a configurator or a service with thousands of variants may require a different policy.
Pagination — block or keep?
Pagination shouldn't be blocked automatically, because it may be Google's only path to products on the later pages of a category (e.g. /chairs/page/2/, /chairs/page/3/).
A good solution should provide a separate URL for each page, ordinary HTML links to the next pages, a self-canonical on each page, the ability for the robot to reach the products, and no canonical pointing all pages to the first one. The second page shows different products than the first — so it isn't a full duplicate. It doesn't have to be in the sitemap, though; the sitemap should mainly contain the main category and product pages.
Infinite scroll and the "Load more" button. Googlebot doesn't behave exactly like a customer — you shouldn't assume it will click a button and automatically load more products. If you use infinite scroll, a "Show more" button or dynamic AJAX loading, make sure products are also available under ordinary pagination URLs connected with <a href> links. Otherwise Google may only see the first part of the category.
Product variants — one page or separate URLs?
The decision depends on whether the variants answer separate queries and whether they are genuinely different offers.
One URL for variants usually works best when a product differs only in size, a simple colour, a minor parameter or the number of units in a pack (e.g. /basic-t-shirt/, where the customer chooses colour and size). Benefits: one strong page, shared reviews, fewer duplicates, simpler management.
Separate URLs for variants can make sense when each variant has its own demand, separate photos, a substantially different specification, its own SKU and stock, can be a standalone destination page, and is presented as a separate offer in ads and the feed (e.g. a 256 GB and a 512 GB phone, a 160 × 200 cm and a 180 × 200 cm mattress). Separate pages should have stable URLs, unambiguous content, correct canonicals, consistent product data and well-thought-out linking between the variants. Don't index 40 variants separately if each shows the same description and differs only by one word in the name.
What to do with a product withdrawn from sale?
Don't use noindex as a universal answer to every unavailable or removed product.
The product will return to sale: keep the same URL, a 200 code, the description, reviews, similar products and a notify option. Don't remove the product from the index on every short change in stock.
There's a new version of the product: set a 301 redirect to the direct successor (e.g. /model-x-2024/ → /model-x-2026/).
No successor, but a sensible category exists: you can redirect to the category if it genuinely helps the customer find very similar products. Don't do this automatically for the whole catalogue.
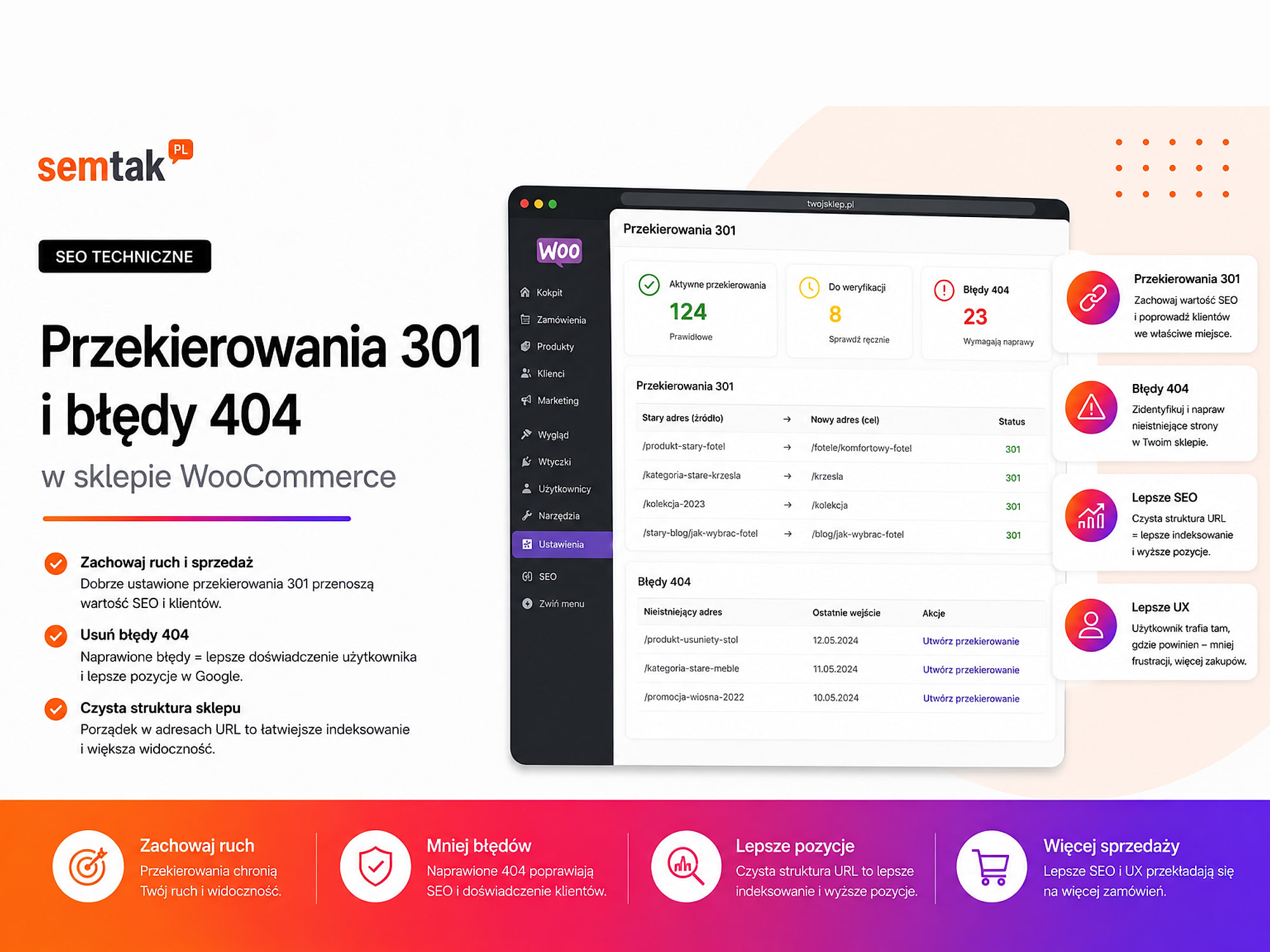
There's no equivalent: leave a correct 404 or 410 error. Don't redirect every removed product to the homepage. We describe the detailed rules in the guide 301 redirects and 404 errors in a WooCommerce store.
Noindex, canonical, robots.txt, 301 or 404?
Each mechanism solves a different problem.
noindex tells the search engine: "you may visit this page, but don't show it in the results".
<meta name="robots" content="noindex, follow">Use it for things like the cart, checkout, search results, account, random archives and technical filter results. For Google to see noindex, it must be able to visit the page.
The canonical indicates the preferred URL among several identical or very similar versions.
<link rel="canonical" href="https://shop.com/chairs/">It can be useful for sorting, tracking parameters, technical URL variants and duplicates of the same page. The canonical is a hint, not an absolute command — Google may choose a different URL if the other signals are contradictory. That's why the canonical, internal links, sitemap, redirects, HTTPS version, hreflang and structured data should all be consistent.
robots.txt specifies which URLs the robot shouldn't download. It can limit wasting resources on infinite parameter combinations, technical endpoints and unnecessary back-end paths. It doesn't guarantee a URL's removal from the results, though — Google may know a URL from links and show it without a description, even though it hasn't downloaded the content. Don't use robots.txt as a substitute for noindex.
The 301 redirect means a permanent move of a page. Use it when a slug has changed, two categories have been merged, a product has a new equivalent, the URL structure has changed, or a page has been moved. The redirect target must be topically similar.
404 and 410. A 404 code means the page wasn't found; a 410 code says it has been permanently removed. They're correct when there's no successor, the URL was created by mistake, the page has no value, or there's no sensible redirect target. A single 404 isn't an SEO disaster — the problems are dead internal links, the loss of valuable URLs and a large number of errors resulting from an uncontrolled change of structure.
noindex and robots.txt don't protect private content
Customer data, B2B documents and partner panels aren't secured with robots.txt or noindex — they require login, the right permissions and server-side protection. Search engine tags are visibility instructions, not an access-control mechanism.
Why isn't it worth using all the mechanisms at once?
The problem isn't the number of settings, but sending contradictory signals. An example of a bad configuration: a page has noindex, the canonical points to the category, the URL is blocked in robots.txt and at the same time it's in the sitemap. Google then receives several pieces of information at once: don't index, treat as a duplicate, don't visit, and "the URL is important enough to be placed in the map". Instead, choose the solution that matches the main problem:
| Problem | The right question | Typical solution |
|---|---|---|
| The page shouldn't appear in Google | Should it still work for the customer? | noindex |
| The page is a duplicate | Which URL should be the main one? | Canonical |
| The page has been moved | What is its successor? | 301 |
| The page has been removed | Is there a sensible equivalent? | 404, 410 or 301 |
| The robot wastes time on infinite parameters | Does the URL need to be crawled? | Link management and robots.txt |
| The content is private | Who can see it? | Login and permissions |
What should the XML sitemap look like?
The sitemap should contain the URLs you want to index, not a full list of everything that technically exists.
The map should include the homepage, indexable categories and subcategories, products, valuable brand pages, SEO landing pages, guides and important information pages. It shouldn't contain noindex URLs, redirects, 404 and 410 errors, the cart, checkout, account, search results, sorting, random filters, non-canonical duplicates or drafts. Every URL in the sitemap should return a 200 code, be indexable, have a canonical pointing to itself and present the right content.
For a larger store it's worth splitting the maps into products, categories, posts, pages and brands or other controlled taxonomies — this makes it easier to determine which type of page Google isn't indexing correctly.
The lastmod parameter. The last-modified date should change after a significant update to the page (a change to the description, the addition of important parameters, an update to the offer, a content rebuild). It shouldn't update on every user visit or on a minor technical change unrelated to the content.
Internal linking and indexing
Google recognises important pages more easily when ordinary, logical links point to them.
The most important categories should be reachable through the menu, the homepage, parent categories, breadcrumbs, guides and related-category sections. Products should receive links from categories, internal search results, recommendations, articles and bestseller lists. If a product is only on the 15th pagination page and isn't linked anywhere else, it may be visited less often.
Orphan pages. An orphan page has a correct URL and may be in the sitemap, but no internal link points to it. Google can find it, but the store's structure doesn't show that it's important. Typical orphan pages are old products, unlinked categories, campaign landing pages, posts after a menu change and brand pages created by an import. The sitemap doesn't replace good navigation.
How to check a store's indexing in Google Search Console?
The "Page indexing" report shows indexed, excluded, blocked, redirected, not-found and duplicate-considered URLs. Not every entry in the "Not indexed" section is an error — if it contains the cart, filters, redirects and noindex tags, the report may be confirming that the configuration works correctly. The problem starts when Google excludes a main category, an important product, a brand page or a sales-generating guide.
"Discovered — currently not indexed". Google knows the URL but hasn't visited it yet or hasn't considered it important enough. Possible causes: weak linking, a large number of unnecessary URLs, a new page, low priority in the architecture, server problems, an overloaded store.
"Crawled — currently not indexed". Google has visited the page but hasn't added it to the index. Possible causes: thin content, similarity to other pages, an empty category, few products, no value compared to an already indexed page, a soft 404, low technical or content quality. Don't solve this by repeatedly clicking "Request indexing" — first improve the page itself and its place in the structure.
"Duplicate, Google chose different canonical than user". Google decided that a different URL better represents this content. Check the canonical, sitemap, internal linking, redirects, parameter versions, HTTP and HTTPS, and www versus non-www.
"Alternate page with proper canonical tag". This can be a correct state if the URL is a technical duplicate and points to the right version. Don't try to index every URL visible in the report.
"Excluded by noindex tag". This is a correct result for the cart and checkout. It's a problem if it affects a page that's meant to earn traffic.
"Blocked by robots.txt". Check whether the block was intentional. If the URL also has noindex, Google may not be able to read that instruction.
"Soft 404". The page technically returns a 200 code but looks removed or empty (a category with no products, a product with a "not found" message, an empty results page, a filter with no available products). Such a page should be filled out, redirected or return the correct error code.
Does the site: command show the number of pages in the index?
The site:yourshop.com command is useful for a quick preview. You can check whether the cart, account, filters, sorting, old subdomains, test versions or outdated products appear. Don't treat the number of results as an exact indexing report, though — for analysis use the page report in Search Console, URL inspection, the sitemap, a store crawl and server logs first.
How to plan an indexing policy step by step?
Step 1. Collect all URL types. Don't limit yourself to URLs from the sitemap — gather URLs from a crawl, Search Console, Google Analytics, the sitemap, server logs, external links, parameters generated by filters and the WooCommerce panel.
Step 2. Group the URLs: products, categories, brands, filters, sorting, pagination, search, tags, cart and checkout, blog, legal pages, old URLs, attachments.
Step 3. Define the role of each group. For each type, ask: might a user want to land here directly from Google, does the page have its own intent, does the content differ from other URLs, is the page stable, does it have enough of an offer, can it be linked sensibly, and should it be in the sitemap.
Step 4. Choose the mechanism. First assign index, noindex, canonical, 301, 404 or 410, crawl limitation or authentication to the URLs. Don't start by randomly adding rules to robots.txt.
Step 5. Deploy on a test environment. Check the page's code, HTTP headers, canonical, response status, sitemap, links, filter behaviour and the mobile version.
Step 6. Run a control crawl. The crawler should show indexable URLs, noindex pages, canonicals, redirects, errors, duplicates, orphan pages and link depth. This article covers indexing in detail; if you need a broader review of the other elements — speed, structured data, hreflang, response errors and technical configuration — also use the WooCommerce technical SEO checklist.
Step 7. Monitor after deployment. After the change, watch the number of indexed pages, excluded URLs, category and product traffic, server errors, crawl frequency and Google's choice of canonicals. With a large store, the effects of tidying up indexing don't have to appear immediately — Google has to revisit and reprocess the existing URLs.
The most common WooCommerce indexing mistakes
The most damage is done by: a block in robots.txt instead of noindex, an accidental noindex on a category, indexing all filters, and a pagination canonical pointing to the first page.
- 1. Blocking in
robots.txtinstead of usingnoindex— Google can't enter the page and read the instruction to remove it from the index. - 2.
noindexon an important category — a single change in the SEO plugin's settings can remove a whole product taxonomy from Google. - 3. Indexing all filters — a store with a few hundred products generates tens of thousands of similar pages.
- 4. A canonical for all pagination pointing to the first page — Google gets the signal that the next pages are duplicates, even though they contain different products.
- 5.
noindexon a temporarily unavailable product — the product returns to sale, but it was removed from the index earlier and has to rebuild its visibility. - 6. All URLs in the sitemap — the map contains filters, redirects, errors and
noindexpages, sending contradictory signals. - 7. Changing URLs without redirects — old products and categories start returning 404, even though they exist under new URLs.
- 8. No consistency between the canonical, sitemap and links — the canonical points to URL A, the sitemap contains B, and the menu leads to C.
What can you check yourself?
Most indexing problems can be diagnosed initially without specialist tools.
- Enter
site:yourshop.comand check whether the cart, account, filters or test version appear in the results. - Open the source of the cart and checkout. Check whether they contain
noindex. - Open a category with the
?orderby=priceparameter and check which URL the canonical points to. - Test a single filter and a combination of several filters. Check whether they reach the sitemap or Google's results.
- Open the sitemap and look for
noindexpages, redirects, filters and errors. - Check whether the next pagination pages have separate URLs and ordinary links.
- Verify whether the test environment requires a password or is restricted server-side.
- Record the index/noindex/canonical/301/404 decision for each URL type before changing any settings.
When is it worth handing this to a specialist?
A specialist's help makes sense when the number of detected URLs is many times higher than the number of products, Google chooses different canonicals than the store, or important categories don't make it into the index.
Consider support when the store has thousands of products, the number of detected URLs is many times higher than the number of products and categories, filters create infinite combinations, Google chooses different canonicals than the store, important categories have a "crawled but not indexed" status, the sitemap contains incorrect URLs, many products are orphaned, the number of indexed pages dropped after a migration, the store uses several SEO plugins, several language versions are running, custom pagination or infinite scroll has been deployed, or the changes have to be made programmatically.
With a larger store it's not enough to tick a single "noindex filters" box. You have to combine the category structure, keyword data, traffic and sales, a crawl, Search Console, canonicals, the sitemap, linking and Googlebot logs. As part of technical SEO you can determine which pages should be indexed, prepare rules for parameters and check the effect after deployment. If the problem also covers content, categories, cannibalisation and the visibility of the whole store, the right starting point may be a store SEO audit.
Frequently asked questions
Should the cart and checkout be indexed?
No. These are operational pages that depend on a specific user's cart. They should have noindex and shouldn't be in the sitemap.
Should all WooCommerce filters be blocked?
No. Most random combinations should stay out of the index, but selected filters that answer real queries can be prepared as separate SEO landing pages.
Does robots.txt remove a page from Google?
It doesn't guarantee that. robots.txt limits crawling. To remove a page from the results, Google should see noindex , a redirect or an appropriate error code.
Should pagination pages have noindex?
You shouldn't do this automatically. Pagination pages help Google reach products further on. They should have unique URLs, ordinary links and, most often, a self-canonical.
What to do with a temporarily unavailable product?
Keep the URL with a 200 code, keep the description and reviews, and show an out-of-stock notice. You can add an availability notification and similar products.
What to do with a permanently discontinued product?
If it has a direct successor, set a 301 redirect. If there's no good equivalent, apply a 404 or 410 instead of redirecting to the homepage.
Is it worth indexing product tags?
Usually not. The exception is tags planned as valuable pages with their own intent, content and a sufficient number of products.
What should be in the WooCommerce sitemap?
Only indexable, canonical URLs that return a 200 code: products, categories, valuable brands, landing pages, guides and important information pages.
Three URL groups, one mechanism per problem
Good WooCommerce indexing comes down to splitting URLs into three groups:
- pages that should earn traffic — categories, products, brands, landing pages and guides,
- pages the customer needs but Google doesn't — the cart, account, checkout, search and technical filters,
- URLs that have been moved or removed — handled by 301, 404 or 410.
Then you need to apply one mechanism that matches the specific problem and keep consistency between the page's code, the sitemap, the canonicals and internal linking.
If you want to check whether Google is indexing the right parts of your store, we can analyse the categories, products, filters, canonicals, sitemap and Search Console reports. As part of technical WooCommerce SEO we'll prepare a decision map and point out specific rules to implement — without blocking pages that should be working for sales.